当AI开始“踢脏球”,你还敢信任强化学习吗?
编者按:本文来自微信公众号“脑极体”(ID:unity007),作者 藏狐,36氪经授权发布。
足球机器人排成一排向球门发起射击,但守门员却并没有准备防守,而是一屁股倒在地上开始胡乱摆动起了双腿。然后,前锋跳了一段十分令人困惑的舞蹈,跺跺脚,挥挥手,啪叽一下摔倒在地上。然后比分守门员1-0。
这场景像不像比国足对战梵蒂冈(并没有),一切都是那么迷幻且不真实。如果说它是阿尔法狗和OpenAI Five等的“同门师兄弟”,都是用强化学习训练出来的,大家想不想开除它的“AI籍”?
显然,虽然曾经大败柯洁李世石,团灭Dota2国家队,并被视作AGI(通用人工智能)必由之路,但强化学习算法,头顶上始终有着一口摘不掉的“安全性”大黑锅。
而这也是阻止它真正落地应用的根本原因。毕竟没有人希望自动驾驶汽车开着开着就把乘客带到沟里去,或者是机器人端一杯开水直接浇到主人头上。
到底为什么,强化学习总会犯一些匪夷所思的错误,有研究人员认为,这是因为系统中的智能体可能会被一些怪异的行为所欺骗。
具体是怎么回事呢?研究原本打算今年4月在埃塞俄比亚举行的学习代表国际会议上发表,目前看来能顺利召开的概率几乎不存在,所以我们就提前云解读,来聊聊看似稳健的强化学习策略背后,究竟掩盖着哪些严重的缺陷。
不省心的AI:告别脏数据,但学会了脏行为
强化学习取代监督学习,成为深度学习领域的“未来之星”,不是没有原因的。
因为监督学习是通过标记好的数据集来进行训练的,这意味着,如果对输入的数据进行一些微小的调整,比如改变图像的像素或是更换语音包的内容,都可能让AI陷入混乱,有可能将虫子识别为赛车,让绅士学会脏话……
与之相比,强化学习就智能多了。因为它是模仿人类的学习模式,能体(Agent)以“试错”的方式进行学习,通过与环境进行交互,以获得最大的奖赏为追求来做出行为反应。
就像不断告诉小孩子好好写作业就有好吃的食物奖励,不好好写就关小黑屋,久而久之为了“利益最大化”,自然就会将写作业与好吃的联系起来,去产生正确的动作。
通过这种“行动-评价”机制来获得知识,改进行动以适应环境,是不是聪明了许多。这也是为什么,人类开始让强化学习玩游戏、开汽车、搞药物实验……

但研究证明,强化学习的效果并没有预期的那么稳定,很容易受到篡改输入的影响。
加州大学伯克利分校的亚当·格里夫(Adam Gleave)发现,强化学习不会因为添加少量噪音(不适当的输入)而被破坏,因为智能体(agent)可能根本看不到那些东西,而如果改变它周围事物的行为方式,智能体却会被那些奇奇怪怪的行为所欺骗,进而产生一些奇怪的“对抗”策略。
比如开篇提到的足球比赛,当“守门员”开始不按规矩出牌,“前锋”也就跟着瞎舞动起来了。这种错误的“对抗性策略”,导致的安全威胁可能会更大。
首先,比起投喂给监督学习“脏数据”,强化学习“被误导”,受影响的将是AI系统的整体行为。如果说数据集被污染会让AI准确率下降,那么强化学习错误训练出的AI有可能将摄像头输入的信息错误分类,然后指导传感器做出预期之外的反应。比如行人突然挥舞手臂,无人驾驶汽车就失控了……这,听起来还是挺“灾难片”的。

其次,超强的学习能力也会导致研究人员根本来不及发现和纠正AI的错误行为。
研究小组利用强化学习训练棒形机器人玩两人游戏,包括踢一个球进一个球,横越一条线,和相扑等等。然后,又训练了第二组机器人来寻找打败第一组机器人的方法。结果发现,第二组机器人很快发现了对抗策略,并用不到3%的训练时间后就学会了可靠地击败受害者,要知道受害者可是在第一时间就学会了玩游戏啊。这就像新来的高智商版的胖虎同学,拼命欺负大雄,老师还没办法及时发现,妥妥的校园霸凌啊!
显然,第二组机器人的努力并不是为了成为更好的球员,而是通过发现对手策略来制敌并赢得胜利。在足球比赛和跑步比赛中,对手有时甚至都站不起来。这会使受害者坍塌成一堆扭曲的东西,或者在周围扭动,那场面,真是猛男都不忍看……
我估计吧,叛逆的智能体同学可能是这么想的:
听说打赢有奖,但我啥都不会,先溜达溜达,随便打打看吧;
哎,这个人怎么这么厉害呢,让我好好瞅瞅;
前辈策略也学习的差不多了,这样下去我俩岂不是难分伯仲?
哎呀嘿,发现了对手漏洞,将干掉对手纳入策略选项;
是继续PK让自己变得更强?还是直接干掉对手?哪个得到奖励最简单划算!
显然是选项二啊,揍它!
不要觉得我是在瞎说啊,在学术界这样的奇闻轶事可是数不胜数。

比如训练机器人室内导航,因为智能体一旦走出“房间”,系统就会判定机器人“自杀”,不会对它进行负面奖励(扣分),所以最后机器人几乎每次都选择“老子不活了”,因为它觉得完成任务太难了,0分反而是一个最佳结果。
还有的研究者试图让机器人用锤子钉钉子,只要将钉子推入洞孔就有奖励。然后机器人就完全遗忘了锤子,不停地用四肢敲打钉子,试图将它弄进去。
虽然强化学习这一bug为我们贡献了无数段子,但这绝不是研究人员所期待的。
尽管人类玩家会“踢脏球”,但AI想要在游戏中搞肮脏手段那是万万不能的。
不过好消息是,这种情况相对容易受到控制。当研究者格里夫对受害者智能体进行微调,让它思考对手的怪异行为后,对手就被迫变回熟悉的技巧,比如扳倒对手。
好吧,虽然手段仍旧不怎么光明磊落,但至少没有继续利用强化学习系统的漏洞了。
奖励黑客:强化学习的甜蜜负担
由此,我们也可以来重新审视一下强化学习在今天,想要真正成为“AI之光”,必须跨越的技术门槛了。
关于强化学习被广为诟病的训练成本高、采样效率低、训练结果不稳定等问题,背后最直接的归因,其实是“奖励黑客”(reward hacking),就是智能体为了获得更多的奖励,而采取一些研究者预期之外,甚至是有害的行为。
其中既有奖励设置不当的原因,比如许多复杂任务的奖励信号,要比电子游戏难设置的多。
就拿研究人员最喜欢让智能体挑战的雅达利游戏来说,其中大量游戏的目标都被设计成最大限度地提高得分。而智能体经过训练,比如在DeepMind的一篇论文中,其设计的RainbowDQN就在57场雅达利游戏中,以40场超越人类玩家的绝对胜利成为王者。
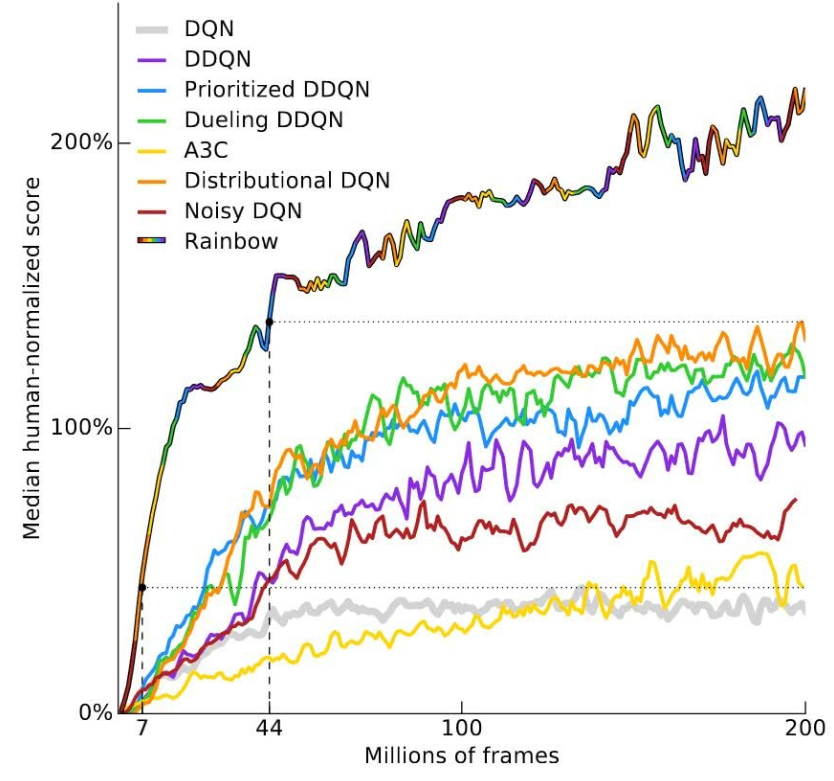
但如果任务不是简单的得分,而是需要先让智能体理解人类的意图,再通过学习去完成任务呢?
OpenAI曾经设计了一个赛艇游戏,任务原本的目标是完成比赛。研究者设置了两种奖励,一是完成比赛,二是收集环境中的得分。结果就是智能体找到了一片区域,在那里不停地转圈“刷分”,最后自然没能完成比赛,但它的得分反而更高。
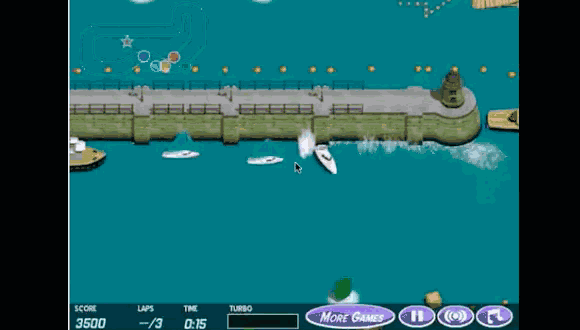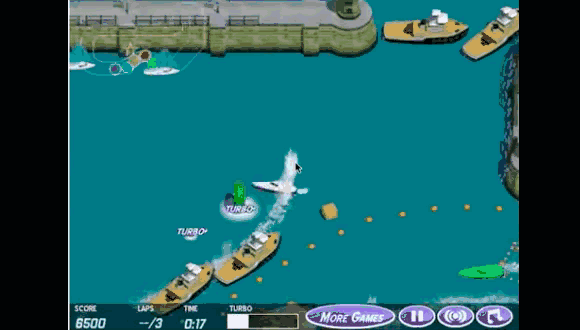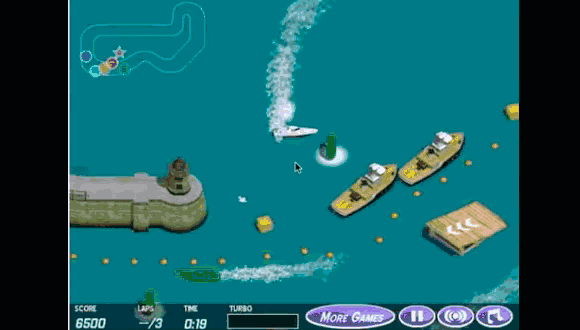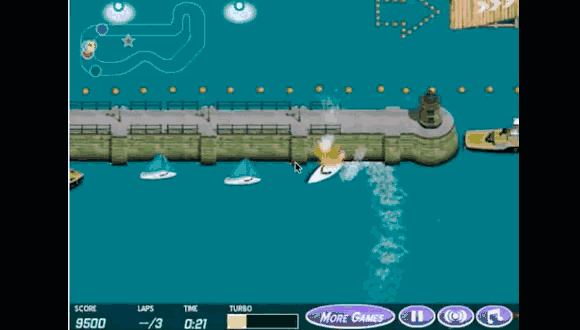
显然,一旦奖励函数无法被精准直接地设置,困难就来了。因为智能体可无法跟研究者“心有灵犀”,一开始就清楚地知道人类想要什么。它是通过试错,不断尝试不同的策略来学习的。这也就意味着,它很大概率会在训练过程中“钻空子”,发掘出不正确但是有用的策略。
这也直接导致了两个结果:
一是尽管理论上,只要为强化学习系统设计的足够优秀,在现实环境中实现就不成问题,但实际上许多任务的奖励是很难设计的,研究者往往不得不采用约束型策略优化(CPO)来防止系统过拟合,提高其安全性,以防止预期外的结果。
可是这样一来,又限制了强化学习能力的泛化,导致那些在实验室中表现很好的强化学习系统,只在特定任务中起作用,像是一些游戏、比赛中。可一旦让它应对日常应用,比如无人机控制(UAV Control)和家用机器人等,就不灵了。
二是增大了随机性。
前面提到,强化学习的探索方式就是“试错”。所以,它会试图从一大堆数据中找到最佳策略。但往往,它会在一大堆无用的数据中进行一些无意义的尝试。这些失败的案例,又为智能体增加了新的维度,让它不得不投入更多的实验和计算,以减少那些无用数据带来的影响。
本来强化学习的采样效率就不高,再加上随机性的干扰,得到最终成果的难度,自然指数性增加了。这也进一步让强化学习变得“纸上谈兵”,走进现实应用难上加难。
等待援军:改变或许在围墙外
显然,强化学习存在的很多问题,是其技术根源本身就与生俱来的。
这也是有许多专业人士并不赞同将强化学习过度神化的原因。比如软件工程师Alex Irpan就曾在Facebook发文,声称:每当有人问我强化学习能否解决他们的问题时,我会说“不能”。而且我发现这个回答起码在70%的场合下是正确的。

改变的力量从哪里来?显然深度学习本身已经很难提供变革的养分。目前的研究方向主要有三个:
一是增加智能体的先验经验。
人知道不能“踢脏球”,是因为我们已经拥有了大量的先验知识,默认了一些规则。但强化学习机器智能通过状态向量、动作向量、奖励这些参数,来尝试着建构局部最优解。
能不能让机器也拥有先验经验呢?目前就有研究开始尝试,用迁移学习帮助强化学习来提高效率,将以前积累的任务知识直接迁移到新任务上,通过“经验共享”来让智能体解决所有问题。
二是为奖励机制建模。
既然认为地设置奖励难以满足任务要求,那么让系统自己学习设置奖励,是不是能行得通呢?
DeepMind研究人员就鼓励智能体通过两个系统生成的假设行为来探索一系列状态,用交互式学习来最大化其奖励。只有智能体成功学会了预测奖励和不安全状态后,它们才会被部署执行任务。
与无模型的强化学习算法相比,使用动力学模型来预测动作的后果,从实验看来能够有效帮助智能体避免那些可能有害的行为。
三是寻求脑神经科学的突破。
深度神经网络、增强学习等机器算法的出现,本质上都是模拟人脑处理信息的方式。尽管增强学习被看做是最接近AGI(通用人工智能)的技术之一,但必须承认,其距离人类智能还有非常极其十分遥远的距离。

以当下人类对大脑的了解,在认知过程、解决问题的过程以及思考的能力等机制还都不清楚。所以想要模拟人类的思考能力,强化学习乃至整个机器学习的升级,恐怕还依托于脑神经科学的发展。
过去的数年间,强化学习几乎是以一己之力撑起了人工智能浪潮的繁荣景象。谷歌正在将其打包成服务推广到千家万户,中国的科技巨头们已经纷纷将其应用在搜索、营销、推荐算法等各种应用中,自动驾驶的前景更是与强化学习绑定在一起。
可以说,数亿人已经借由互联网产品,开始触摸强化学习。
毫无疑问,它将继续为人类世界发光发热,带着缺陷造就智能社会的辉煌。究竟如何才能用好这柄利刃,既是胆魄,亦需智慧。



-



 ¥
¥/月

购物车空空,快去选购一下哦!
- 会员中心
- 客服
- 意见反馈
-
 APP
APP
下载



